The Virtual Internship: My Experience
Monday, July 13, 2020,
8 min read
These summers, I interned at one of the largest travel companies of the world, Expedia Group™️. Who knew during a pandemic when travel is at an all time low, Expedia had a great intern program planned for us!
Luckily, my previous intern was remote too, so I was kind of used to work from home. In this internship, I majorly worked on cloud and data engineering.
The induction week
Expedia organized an induction week for us, and it involved workshops on various topics: how to become a better leader, designer, and we even got to know how Expedia operates. We kept on having workshops throughout our intern, and there was a lot to learn from each session.
My setup

Not the fanciest setup out there, but enough to get the work done :)
My Team - Vrbo: Stayx dot net modernization pod
I was a part of the Stay Experience team, which looks after the post-booking experience for a traveller. The team was divided into pods, and I worked on the .Net Stack Modernisation pod. My work involved making a microservice and figuring out how to deploy it to the cloud.
I worked with a manager and a buddy. We synced up every week and discussed work updates every day. It motivated me to stay on track. I also synced up with our project sponsor a few times. I enjoyed such one on one sessions. They helped me connect with the team better.
All the Vrbo interns together had a weekly sync with the Vrbo managers. We socialized, played some games, get help on some issues. It was nice to have someone for support throughout the program, and these calls also helped me get to know the other interns better.
The project
Motivation
We have a database which stores the notifications for guests of guests in a homestay. Now we wanted a way in which we can store the data in S3 and keep it updated.
- Why are you storing the data in two different places?
- This data is not only used to send a notification but also by an analyst or data scientist. The MongoDB database also backs the GoG API, and if everyone does their operations on MongoDB, it might severely affect the API.
We finally came up with the idea to use a Spark Job. This job would take the data from MongoDB and store it in an S3 bucket.
- Why a spark job?
- Spark and Scala are the industry standard for data management. The jobs will be able to manage huge amounts of data without any hiccups.
Aim: Create a spark job to sync data from MongoDB to S3
A quick revision
This blog is going to get more technical now, just keeping this for a quick reference if you have a doubt.
What’s MongoDB? It’s a NoSQL database.
What’s scala? It’s a programming language widely used for data management. I did all my coding in the Scala language.
What’s Apache spark? It’s a fast and general-purpose cluster computing system for large scale data processing. Some important things to know about spark are:
- Dataframe: This is data in the form of a table, just like a relational database table.
- Dataset: Extension of Dataframes, they provide the functionality of being type-safe and an object-oriented programming interface.
- SparkSession vs SparkContext: Spark session is a unified entry point of a spark application from Spark 2.0. It provides a way to interact with various spark’s functionality with a lesser number of constructs. Instead of having a spark context, hive context, SQL context, now all of it is encapsulated in a Spark session
- Prior Spark 2.0, Spark Context was the entry point of any spark application and used to access all spark features and needed a sparkConf which had all the cluster configs and parameters to create a Spark Context object
What’s a spark job? In a spark application, when you invoke an action on RDD, a job is created. It’s the main function that has to be done and submitted to spark.
What’s a vault? Hashicorp Vault is a tool for secrets management, encryption as a service, and privileged access management.
What’s an S3 bucket? Just a simple distributed file storage system, think of it like the hard disk on your computer

Approach
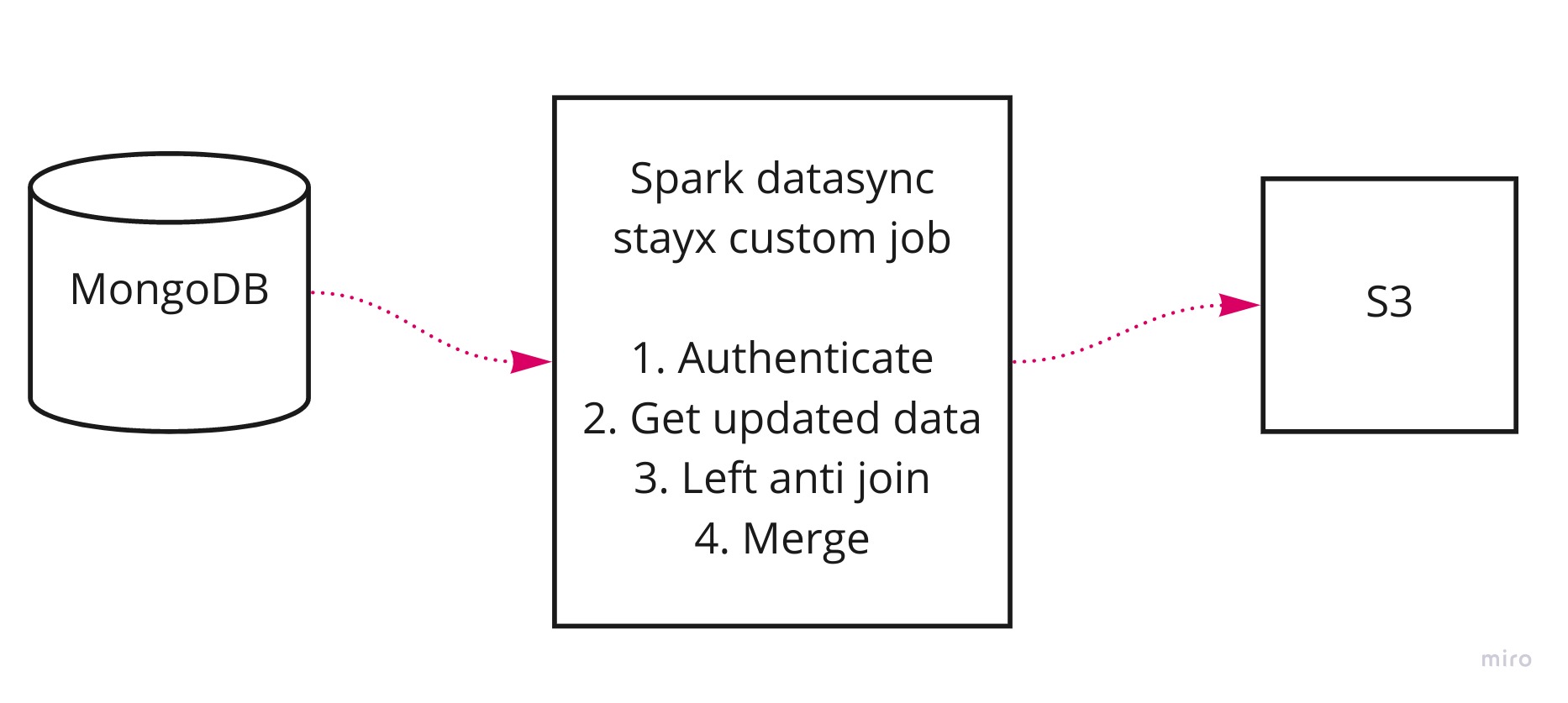
The spark job
- Authenticates the vault and gets the secrets
- Reads the updated data from MongoDB
- Reads the data stored as parquet in S3 bucket
- Does a left anti join on s3 and mongo data, you now have the data that did not change
- Merge the data that didn’t change with the new data with the new data
- Write the data as parquet in S3 bucket
The authentication was a little better than just sending a saved token:
- Grab the EC2 metadata and nonce
- Send the metadata and nonce to Vault
- Vault checks if the EC2 instance is allowed and the nonce is correct
- Obtain secrets like AWS access and secret key, and MongoDB password
- Send a nonce to the Vault server and get the token
- Get the secrets via the token
Here’s a nice example explaining everything:
Mongo
id author book updateTime
1 A1 B1 T1
2 A2 B2 T2
3 A3 B3 T3
4 A4 B4 T4
S3
1 A1 B1 T1
2 A2 B2 T2
3 A3 B3 T2.1
Step 1:
get all docs from mongoDb between updateTime1 and updateTime2 where T2 < updateTime1 < updateTime2
fetched records:
3 A3 B3 T3
4 A4 B4 T4
Step 2:
read all records from S3.
fetched records:
1 A1 B1 T1
2 A2 B2 T2
3 A3 B3 T2.1
Step 3:
Left anti join on id between S3 and mongo data so that we have the data that did not change
1 A1 B1 T1
2 A2 B2 T2
Step 4:
Merge results of Step 3 with data fetched in Step 1:
new data set:
1 A1 B1 T1
2 A2 B2 T2
3 A3 B3 T3
4 A4 B4 T4
This can be put back to S3. You can see how this data is in sync with Mongo dataChallenges (and how I tackled them)

- VPN Issues: The VPN I was using did not support Linux or WSL, so I had to work on windows. Windows is not at all developer-friendly. It was challenging to find a workaround for one-line commands in Linux.
- However, I found a hack for this. I created an EC2 instance on the Expedia network and shifted all my work to that. Not only I could access all the links, but the scripts ran much faster than on my computer.
- RAM Issues: I initially was using IntelliJ since it was easier to setup a scala project with it. Intellij was terribly slow and took a lot of RAM.
- I later switched to VSCode plus Metals. Although it was a little more time consuming to setup, once understood, all RAM issues were solved, additionally using bloop instead of sbt decreased compile time.
- Having a local MongoDB server for testing was also quite RAM hungry, MongoDB Atlas helped me a lot here. I deployed a free cluster in the cloud, and my work was done :)
- Spark and MongoDB
- Spark has some underlying concepts which were a little nontrivial to understand, at least for a first-timer like me. Above that the documentation of MongoDB-Spark connector was following old spark conventions at one place and new ones somewhere else. The documentation confused me a bit.
- Understanding Vault EC2 authentication
- Authentication took most of the time, being a college student, I really didn’t worry about securing my applications in projects. Since we really didn’t put something into production.
- I learned about Hashicorp Vault(Store secrets), Terraform(Build instances from code) and Consul(Backend for Vault)
- Rather than having a token to authenticate vault and get the secrets, a better method would be to use the ec2 metadata in which the spark job will be running to authenticate vault.
- Making EC2 instances with Terraform and Consul
- Setting up EC2 instances
- I had some trouble finding the correct configurations so that I am able to SSH into an instance and make sure the instance can access all VPN links.